
Model for bleeding a webserver cluster
Today on the subway I thought about server bleeding, and when I got to work I took a moment and wrote down my thoughts in the subject. How would one perform a server bleeding for a simple load balanced environment? You can see this as a model if you'd like, for server bleeding in a simple scenario.
What is server bleeding?
Position yourself as a developer for a large e-commerce site. The major income for the company will come through the website and it is a critical requirement that the application is 100% available. How would you perform updates to the application without downtime for releases and testing? If you have a load balanced environment (which would be a must have for the example above) you can choose to update one server at the time and lock out users, but if you don't want to interrupt a user in the middle of placing an order, you will have to bleed the server. When you bleed a server you will let all users active on the server to stay until they leave, and redirect all incoming users to one of the other servers in the cluster. When all the users have left the server you can safely apply your bug fixes and do your testing before connecting it to the web application cluster and start bleeding the next server.
Step by step
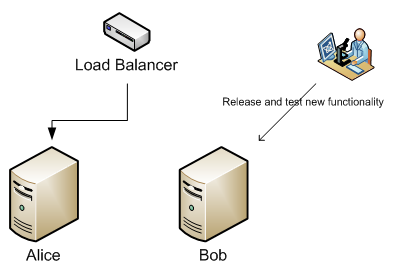
In our enterprise environment we have two servers behind a load balancer. One server is called Alice and the other Bob. It is imperative that the application that Alice and Bob serves will not go offline and that no user should get a bad experience.
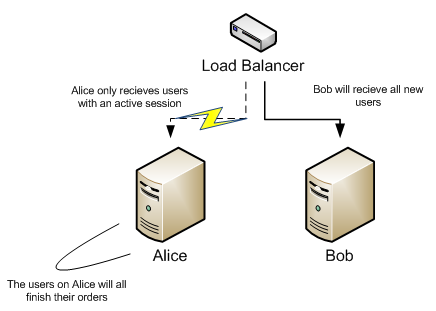
Our first task is to tell the load balancer to redirect all new users to Bob, and only let users with active sessions come to Alice. This way Alice will reduce the number of users as they are leaving the website. This is the process of bleeding. We're bleeding Alice of users until she's bone dry.
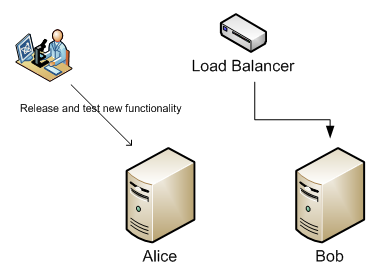
When Alice is empty, we apply our updates and do our testing. This will not affect any users since all users now are at Bob. You have to make sure that Bob can handle the load of both servers. If you're using the load balancer as a failover, you're probably already setup for that.
When Alice is updated and tested we add her back to the cluster and start bleeding Bob. All new incoming users will now get the updated experience from Alice.
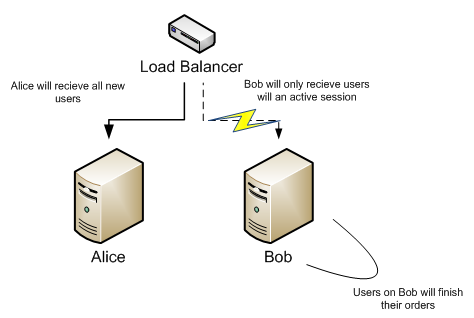
When Bob has no users left we apply the updates to him. We now have a fully updated system without any downtime. Way to go!
There are some limitations to this tecnique. If we're making schema changes in the database we might still have to take down the application in order to fully release and test the changes before letting the users back into the servers. There are however other ways to get around that problem. You can have a release environment where you can do all your changes and then just switch over to. But setting up a mirrored production environment is not easier than doing server bleeding and certainly not cheaper ;)